Reinforcement learning on Atari games/OpenAI gym
This project was carried out as part of the TechLabs “Digital Shaper Program” in Aachen (Winter Term 2021/2022)

1. Introduction
Deep reinforcement learning is the closest thing to true artificial intelligence made by humans, because of its ability to learn from its own actions without the need for human supervision. It has been a field of research within Machine Learning for decades. However, lately, great leaps have been made in this field due to the generalisation capabilities of neural networks and increasing computational power. Reinforcement learning has been applied to robotics, autonomous driving, biology and even to controlling nuclear plasma. But one of the most famous ways to use reinforcement learning is in gaming. Here it has already shown super-human performance, for example winning against the world champion in the game Go or the world champions in DOTA2, a 5vs5 multiplayer online battle arena game similar to League of Legends.
In our Techlabs project, we trained a reinforcement learning agent to play the Atari game Ms Pacman, inspired by DeepMind’s paper “Human-level control through deep reinforcement learning” which was published in 2015. Also, you will learn about the core principles of reinforcement learning and how it is possible to interact with a variety of game emulators.
2. Basic Knowledge
In this section, we will explain the basic setup of reinforcement learning and then go into detail about deep reinforcement learning.
2.1. Reinforcement Learning
As with supervised and unsupervised learning, reinforcement learning is a machine learning technique, but it takes a fundamentally different approach. In contrast to learning by analysing data patterns, it is inspired by biological processes. Behaviour strategies are learned by interacting with the environment and receiving feedback in the form of rewards.
The core components of every reinforcement learning set up are: 1. An agent performs actions and tries to optimise the long-term reward. In Ms. Pacman, the agent is the player itself. 2. The environment is the scenario in which the agent takes decision. It changes its state st depending on the agent’s actions. It can be imagined as the agen’s world, for example in Ms. Pacman it’s the game itself. 3. The rewards rt are a return of the environment to the agent. The reward is then used by the agent to know if its actions were good or bad. An example in Ms. Pacman for a positive reward is eating a pill and a negative reward is getting killed by a ghost.
In every time step, the agent chooses an action at and the environment changes its state from st to st + 1. The agent gets the new state st + 1 and a reward rt back.
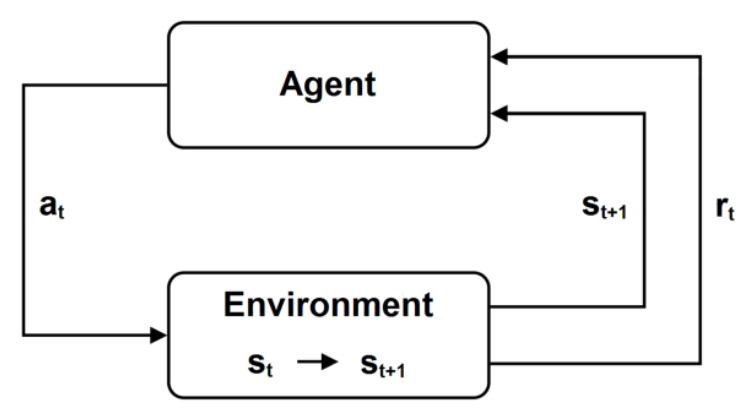
The following notation is used when considering the RL problem:
- The policy function π can be imagined as the agent’s strategy. It is used by the agent to indicate which action to take in state s. A perfect policy function would choose the perfect action in every state, so the agent never looses a game.
- The value function V is used to predict the expected, future rewards. That is necessary because we want the agent to gain the best long-term reward. For that goal it should accept a lower short-term reward. In Ms. Pacman that could mean to eat less pills, but get not killed by a ghost.
- The state space S is the total number of all possible states of the environment, which is incredible high. In tic tac toe for example the total number of possible combinations is 593.
- The actions space A is the set of all the possible actions that can be performed by the agent. In Ms. Pacman these are the joystick movements, which are normally performed by the human.
A policy function (its strategy) is learned by maximising the long-term reward. Trial-and-error is the agent’s method of learning. Because the agent does not know the policy at the beginning, it chooses random actions. As training increases, the agent learns which actions maximise rewards for each state and adjusts its policy accordingly.
2.2. Deep Reinforcement Learning
Deep Reinforcement Learning is the combination of deep neural networks and reinforcement learning. A deep neural network can be used to approximate a value function, policy computation, or state computation in such a scenario. A Convolutional Neural Network computes a simplified state from pixels in an image in the case of Deep Reinforcement Learning for video games.
2.3. What is Gym?
Gym is an open source library, which provides environments for reinforcement learning tasks. It is created by OpenAI to provide better benchmarks and environment standardisation for publishing results in AI research. The library offers a variety of different environments with various difficulties, e.g. balancing a pole with a cart, Atari games (as used in this project) or controlling a robot hand. It can be easily installed via pip/conda and used in your Jupyter notebook or IDE. Explore for yourself! (https://gym.openai.com/docs/)
3. Method
Now that you know the basic principles and technical terms, we are going to explain our implementation of an algorithm developed by researchers of DeepMind. The related paper was released in 2015.
3.1 Prerequisites
The core components of the DeepMind’s Deep Q-Learning with experience replay algorithm are the following:
- Set of states S: An 84x84 pixel image of the game being played.
- Set of actions A: The joystick movements which control the player.
- Reward r: The numerical reward for playing the game.
These components are stored in the form of a tuple, where each tuple contains the current state (st), the action taken (at), the reward received (rt), and the next state (st + 1). The images of states are stored as a matrix where each number corresponds to the greyscale value of the pixel at that location. The actions have been given numerical values, for example UP is 1. The algorithm modifies the reward obtained from the game, where it is clipped between -1 and +1. Some games like Ms. PacMan give ten points for each dot whereas one point is given for breaking the yellow bricks in Breakout. Due to this highly non-uniform score system across games, the reward is clipped to make sure the network learns well for every game. The environment also keeps track of whether the game is over as a Boolean value. This value is stored in the tuple.
To create such a tuple, the action to be taken is provided and the environment returns the next state and the corresponding reward. In the beginning, the agent is allowed to freely explore the environment and take random action. With progressing frames, the agent restricts exploration and takes those actions that will lead to higher rewards. This action policy is called the ϵ-greedy policy and is one option to deal with the exploration vs exploitation dilemma.
A Convolutional Neural Network (CNN) is also required for the deep learning portion of this algorithm. The architecture of CNN is simple. It takes as input an 84x84x4 pixel image. Then, it has three convolutional hidden layers followed by a fully connected layer. The output layer is a fully connected linear layer with a single output for each valid action.
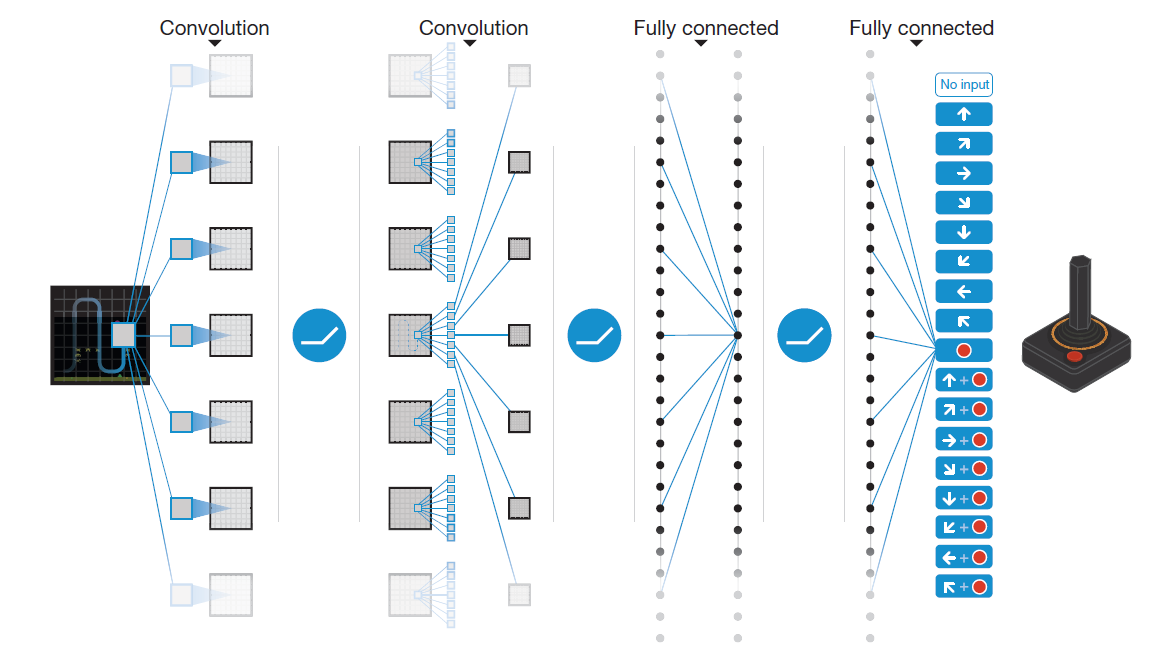
Source: Human-level control through deep reinforcement learning, Minh et. al., Nature Vol. 518, Pg. 530
3.2 Training
Before training, a sample buffer of experiences is built, which is a storage of the tuples. The algorithm gives these training steps:
- With probability of ϵ, choose the action at. This is the ϵ-greedy policy discussed above. Epsilon is initially chosen high (equal to 1) and then gradually decreased to 0.1.
- Create the tuple of experience when the agent takes this action and the environment returns us the corresponding reward rt and the next state st + 1. Store this tuple in the experience replay.
- From the experience replay, randomly select a batch of tuples for training and pass these parameters to the main CNN network. The network then processes the batch of next states and outputs the Q value. This is used to calculate the target values y as the following:
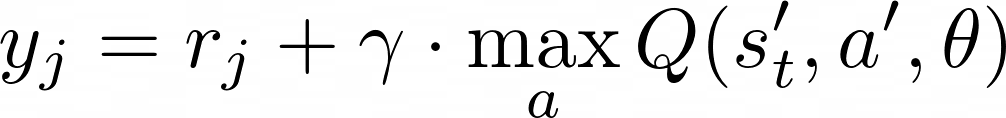
- where j∈ 1 to batch size, γ is the discount factor, and θ are the parameters of the main network.
- Calculate the loss of the network as:
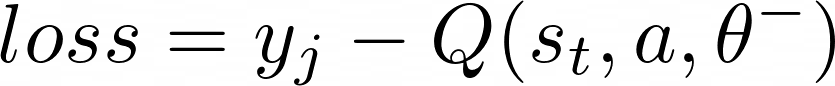
- where the second part of the loss equation comes from the target network with parameters θ−. The batch of current states is given as input to the target network and it also outputs Q-values. The value corresponding to the action in the tuple is used in the above loss equation.
- Update the main network using this loss function. The paper recommends clipping the loss between -1 and +1 as well. Huber loss, or the smooth L1 loss can be used for this purpose. This form of error clipping further improves the stability of the algorithm.
- After updating the main network every 1000 steps, the target network is updated by setting its parameter equal to the main network. The benefit of using two such parallel CNN networks is discussed further.
3.3 Further discussions
In the first phase of the project, we tried to implement DeepMind’s algorithm from Human-level control through deep reinforcement learning. Two major changes to simply using neural networks with Q-Learning have been introduced in the paper, which greatly increases the performance of the algorithm.
- The first method uses two neural networks, namely the main network and the target network. This second target network is used to generate the target value (y, in a regular neural network) to be compared against the predicted value (ŷ, in a regular neural network). The parameters of the target network are updated only after certain steps to ensure the same target value output. Using the target network which is only periodically updated reduces correlations.
- The second change is using an experience replay, which is essentially the storage of tuples. Each tuple contains the current state, the action taken, the reward received, and the next state. Tuples are randomly sampled in batches from this replay buffer to be fed to the main network. When we sample randomly, no consecutive samples are given to the network, which means there is very little correlation between them. This ensures better learning.
4. Project Result
Taking into consideration the fact that it usually takes weeks to fully train such a network, even while using a GPU, we were limited in the availability of resources. The graph below, which plots the Q-value against the number of training epochs, shows that a significant time is spent with the network failing to learn. The Q-value begins to improve around the 10th epoch. An interesting example of this can be seen in another game, Breakout. Until the agent starts hitting the bricks in such a way that the ball enters the upper portion through a gap created, and then it starts scoring significantly by hitting the upper row of bricks, the agent will not improve.
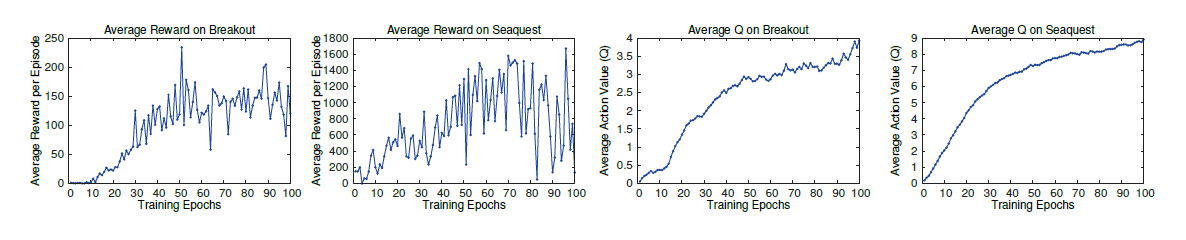
Source: Playing Atari with Deep Reinforcement Learning, V. Minh, et. al., 2013, Pg. 7.: One epoch corresponds to 50000 weight updates or roughly 30 minutes of training time.
Due to these limitations, the training was split into manageable chunks, reducing the number of total frames for which the training ran. This was a disappointing result for our project, as we failed to achieve the desired results, even when using the recommended hyper-parameters in the original paper.
After hours of training on the game Ms Pacman, the agent abled to score the high score of 2650, placing it within the range of scores achieved by DeepMind. Even though a human player can score around 15000, a reinforcement learning agent scoring this high is laudable. There are factors, which are not fixed, as the location of ghosts at different time or the location of bonus points. It makes it more difficult for the agent to maximise future rewards by following a specific strategy. The training was performed on a Nvidia GTX 1050Ti GPU, broken down in chucks of 1 million frames per run. After each run, the network weights, optimiser parameters, and the replay buffer was saved and loaded again for the next run.
5. Conclusion & Outlook
With our work, we were able to successfully implement Deep Q-learning for replicating the score for Ms. Pacman. A natural extension of our project would be implementing transfer learning to other Atari 2600 games and validating the scores with those reported in the paper. For transfer learning, two approaches would be the most appropriate: fine-tuning and the actor-mimic method.
- Fine-tuning:
In the fine-tuning approach the end layer of the CNN agent is replaced to match the action outputs of the specific game. Random weights are assigned to the last layer of the CNN agent while the weights in the previous layers are not changed. The saved replay buffer is then reused and the agent is retrained for a diminished number of epochs, compared to training the agent from the beginning. With this procedure, the agent is able to reach the required high scores with minimal games.
2. Actor-Mimic Method:
The Actor-Mimic method is a novel method of multitask and transfer learning that enables an autonomous agent to learn how to behave in multiple tasks simultaneously, and then generalise its knowledge to new domains. It exploits the use of deep reinforcement learning and model compression techniques to train a single policy network that learns how to act in a set of distinct tasks by using the guidance of several expert networks, or so-called ‘teachers’. However, this method requires the availability of a domain specific benchmark models to enable the training of a generalised model.
Another possible extension of the work in this project would be to explore alternative approaches for training such as Policy Gradient. PGs are proven to perform better after fine-tuning compared to DQN. Also, they are considered to be a better end-to-end approach, since there exists an explicit policy directly optimising the expected reward. However, some challenges exist, such as the requirement of large samples and debugging inefficiencies, making simple PG implementations slower to converge.
6. Sources
- OpenAI defeats DOTA 2 World Champions https://openai.com/blog/openai-five-defeats-dota-2-world-champions/
- Degrave, J., Felici, F., Buchli, J. et al.: Magnetic control of tokamak plasmas through deep reinforcement learning (2022) DOI: 10.1038/s41586–021–04301–9
- Del Pra, Marco: Introduction to Reinforcement Learning (2020) https://towardsdatascience.com/introduction-to-reinforcement-learning-c99c8c0720ef
- Mnih, V., Kavukcuoglu, K., Silver, D. et al.: Human-level control through deep reinforcement learning (2015) DOI: 10.1038/nature14236
- Joshi, Ameet V.: Machine Learning and Artificial Intelligence (2020) DOI: 10.1007/978–3–030–26622–6
- Li, Yuxi: Deep Reinforcement Learning: An Overview (2018) arXiv:1701.07274v6
- OpenAI Gym Environment https://gym.openai.com/
- Deep Reinforcement Learning: Pong from Pixels https://karpathy.github.io/2016/05/31/rl/
- Benchmark of algorithms playing Atari games https://paperswithcode.com/sota/atari-games-on-atari-2600-venture
Team Members
Abhilash Ingale
Yannick Pellenz
Sumit Bhamare
Marek Fencl
Mentors
Evelina Masliankova
Alina Dallmann
TechLabs Aachen e.V. reserves the right not to be responsible for the topicality, correctness, completeness or quality of the information provided. All references are made to the best of the authors’ knowledge and belief. If, contrary to expectation, a violation of copyright law should occur, please contact journey.ac@techlabs.org so that the corresponding item can be removed.
